

No cenário atual da programação, muito se fala sobre as Expressões Regulares, elementos de fundamental importância tanto para pesquisas quanto para validação de dados. Com elas, é possível trabalhar de maneira muito mais rápida e eficiente, resolvendo desde tarefas simples do dia a dia até tarefas mais complicadas, em projetos que parecem assustadores.
Porém, ao primeiro contato, as Expressões Regulares podem parecer um monstro de sete cabeças: sem lógica alguma, um emaranhado de letras e símbolos jogados aos montes aleatoriamente.
Sabendo disso, resolvemos criar esta postagem para desmistificar as Expressões Regures, provando uma vez por todas que, além de poderosas, elas podem ser muito fáceis de aprender. Ao final, você certamente verá que deve dedicar um tempinho para aprendê-las.
O que são Expressões Regulares?
Antes de mais nada, precisamos concordar com uma coisa: Expressão Regular é um termo muito grande para ficar digitando, falando e lendo, certo?
Então vamos começar a chamá-las também pelo nome mais íntimo: RegEx (do ingles Regular Expression).
Agora sim! Vamos à definição de RegEx. Para isso, deixo aqui a definição formal encontrada por toda a web (no caso, retirada da Documentação Oficial da Mozilla):
“Expressões Regulares são padrões utilizados para selecionar combinações de caracteres em uma string.”
De uma forma mais simples, podemos falar que as Expressões Regulares são strings especiais para buscar padrões em textos. Algo como um CTRL+F bem poderoso!

Porque e quando usamos as Expressões Regulares?
Nós usamos esse “super CTRL+F” no mesmo modo que o CTRL+F normal, ou seja, para buscas em textos.
Para entender melhor seu uso, vamos pensar em uma frase simples, como a seguinte:
“O Felipe nasceu em 1996 e desde 2007 estuda programação. Em 2019 ele fundou a ByLearn. Em 2020 já existem milhares de ByLearners pelo mundo.”
Neste exemplo, para encontrar o ano em que eu nasci, eu digitaria “1996” na busca. Para encontrar o ano inicial da ByLearn eu procuraria por “2019” e por aí vai…
Mas e se eu quisesse encontrar todas as datas presentes no texto?
Bem, pra isso eu teria que ficar louco no CTRL+F e provavelmente acabaria tendo que lero texto todo para encontrar manualmente cada uma das datas. Usando as Expressões Regulares, no entanto, eu poderia simplesmente falar:
“Hey, busca pra mim tudo o que é formado por 4 números seguido um do outro”
Viu? Simples assim!
Além disso, como você deve saber, na ByLearn nós temos algumas expressões nossas, como por exemplo, ByLeaner, para nos referirmos aos nossos alunos.
Podemos então validar uma palavra para saber se ela é um termo próprio nosso, no caso, se ela começa com “ByLearn”. Sendo assim, eu falo para o RegEx:
“Hey, veja se essa palavra aqui começa com ByLearn”
Pronto! Conseguimos validar uma palavra utilizando apenas o RegEx.
Mas e na vida real?
Analisando agora um caso real: eu posso criar um padrão que diga ao RegEx como é a estrutura de um endereço de e-mail ou url de um site e o ele vai verificar aquela string e me dizer se o texto é ou não válido
Sendo assim, podemos concluir que as Expressões Regulares podem ser utilizadas para buscar um padrão em um texto, tanto retornando os matchs (ocorrências) quanto para validar se o texto (ou parte dele) segue as regras do seu padrão.
Ainda em dúvida? Então se liga nesses casos reais de uso de Expressões Regulares que acontecem o tempo todo:
- Validar e-mail
- Validar URL
- Validar formulário para envio
- Verificar força de senha
- Verificar se o CPF está no formato correto
- Buscar palavras-chave em texto
- Extrair informações de sites
- Contar ocorrência de determinadas palavras
- Encontrar tags HTML
- Alterar determinadas letras e termos em um texto
Conhecendo a linguagem do RegEx
Como você pode ter percebido, o RegEx é bem completo, poderoso e eficaz! Para isso, ele precisa de uma “linguagem própria”, uma notação que faça seu motor (engine) saber como deve trabalhar.
Para isso, o RegEx possui algumas propriedades únicas, sendo elas:
- Caracteres: Esse é fácil, são os caracteres normais que conhecemos, como “abc … xyz” , “0 1 2 … 7, 8, 9” e afins;
- Meta Caracteres: São como “Caracteres especiais”, indicando propriedades específicas da linguagem, como “esse caractere indica que algo ocorre uma ou mais vezes” ou “esse caractere indica o início da frase“;
- Meta Sequências: Sequências especiais, que muitas vezes podem ser atalhos para classes de caracteres, como “tudo que for número“, “tudo que for letra“, “palavra que inicia com tal letra“;
- Classes de Caracteres: Define intervalos de aceitação, como “a letra está entre B e L” ou “tudo exceto números entre 4 e 7″;
- Quantificadores: Denota a quantidade de vezes que a ocorrência buscada deve existir, como “tem 4 números seguidos” ou “pelo menos uma vez”.
- Âncora: Define posições na string, como a posição inicial e a posição final;
- Modificadores: Modificam o comportamento padrão das Expressões Regulares;
- Grupos de Captura: Define agrupamentos para se capturar dentro do padrão, como “Procure por letras seguidas de números e me retorne apenas os números“.

Pronto! Agora já sabemos o necessário da linguagem das Expressões Regulares para executar com sucesso as tarefas do dia a dia, mas certamente você está confuso com apenas a parte teórica de cada elemento da linguagem, não é mesmo?
Então continua conosco que, logo abaixo, criamos algumas tabelas para te ajudar a entender melhor o que estamos falando. Selecionamos também exemplos de vários dos elementos explicados acima.
Caractere
Basicamente é o próprio caractere digitado: letra, número ou alguns caracteres especiais (os não presentes nos Meta Caracteres, como letras com acento).
Lembrando que há diferença entre “a” (minúsculo) e “A” (maiúsculo)
Daremos exemplo apenas de um caractere de cada, visto que para toda letra ou número o mesmo será válido.
| Caractere | Descrição | Exemplo |
|---|---|---|
| a | Encontra o Caractere a | “a” |
| A | Encontra o Caractere A | “A” |
| ô | Encontra o Caractere ô | “ô” |
| 1 | Encontra o Caractere 1 | “1” |
| @ | Encontra o Caractere @ | “@” |
Meta-Caracteres
São caracteres especiais, que possuem uma função específica nas Expressões Regulares.
Não se preocupe caso não entenda algum termo, todos eles serão explicados no decorrer do texto e no final teremos alguns exemplos!
| Caractere | Descrição | Exemplo |
|---|---|---|
| \ | Caractere de Escape. | “\.” |
| \ | Início de Meta-Sequência. | “\w” |
| [] | Classe de Caracteres. | “[a-z]” |
| () | Grupo de Captura | “(By)” |
| {} | Número de ocorrências (Quantificador) | “{2}” |
| * | Qualquer quantidade (Incluindo Nenhuma) | “1*” |
| + | Ao menos uma ocorrência | “1+” |
| ? | Uma ou nenhuma ocorrência | “1?” |
| | | Um ou outro | “1|2” |
| ^ | Início da linha | “^ByLearn” |
| $ | Fim da linha | “ByLearn$” |
| . | Qualquer caractere exceto o Nova Linha | “By…rn” |
Caractere de Escape e Meta-Sequência
Para poder digitar tais caracteres especiais como caracteres simples (iguais os acima), você deverá usar o Caractere Especial de Escape.
Ele fará com que o próximo Meta-Caractere digitado seja interpretado como um caractere normal, como por exemplo “\.” para usar o caractere do ponto ou “\+” para usar o caractere do símbolo de mais.
Inclusive, para usar o caractere comum do barra invertida, precisamos usar duas barras (“\\“), afinal, a primeira é o Escape da segunda.
Todavia, o barra investida (Espape) também inicia Meta Sequências (como você verá logo abaixo) em alguns determinados caracteres simples.
Ou seja, além de transformar Meta Caracteres em Caracteres Simples, ele pode ser uma faca de dois gumes e fazer o oposto.
Sendo assim, devemos tomar um cuidado especial quando formos usar tal caractere.
Classe de Caracteres
Classes de Caracteres definem um intervalo de aceitação/negação, ou seja, tudo o que tiver dentro do intervalo poderá ser aceito ou negado.
| Classe | Descrição | Exemplo |
|---|---|---|
| [abFg] | São aceitos: a, b F e g | “[abFg]” |
| [159] | São aceitos: 1, 5 e 9 | “[159]” |
| [a-z] | São aceitos: a até z | “[a-z]” |
| [A-Z] | São aceitos: A até Z | “[A-Z]” |
| [aA-zZ] | São aceitos: a até Z | “[aA-zZ]” |
| [0-9] | São aceitos: 0 até 9 | “[0-9]” |
| [aA0-zZ9] | São aceitos: a até Z e 0 até 9 | “[aA0-zZ9]” |
| [^a4] | Tudo exceto: a e 4 | “[^a4]” |
| [^a-z] | Tudo exceto: a até z | “[^a-z]” |
| [^0-9] | Tudo exceto: 0 até 9 | “[^0-9]” |
| [(*|+)?.$] | São aceitos: (, *, |, +, ), ?, . e $ | “[(*|+)?.$]” |
Reparou em algo intrigante no ultimo exemplo?
Os Meta-Caracteres “(*|+)?.$” foram lidos como caracteres normais, pois dentro das Classes de Caracteres eles não possuem seus “poderes especiais“.
Meta-Sequências
Chegamos nas Meta-Sequências, muitas vezes são consideradas atalhos para as Classes de Caracteres e Meta-Caracteres, facilitando, e muito, a utilização de RegEx.
Por exemplo, podemos substituir o uso de “[aA0-zZ9]” por apenas um “\w” (minúsculo) e sua negação (“[^aA0-zZ9]“) em um simples “\W” (maiúsculo).
| Sequência | Descrição | Exemplo |
|---|---|---|
| \w | São aceitos: Valores alfanuméricos | “[\w]+” |
| \W | Tudo exceto: Valores alfanuméricos | “\W” |
| \d | São aceitos: Valores numéricos | “\d\d” |
| \D | Tudo exceto: Valores numéricos | “[\D]?” |
| \s | São aceitos: Espaços | “1\s+2” |
| \S | Tudo exceto: Espaços | “[\S]*” |
| \b | São aceitos: estar no início ou fim da palavra | “\bBy”, “Learn\b” |
| \B | Tudo exceto: estar no início ou fim da palavra | “By\B”, “\BLearn” |
| \A | Indica início do texto | “\AEu sou” |
| \Z | Indica final do texto | “o Felipe\Z” |
Quantificadores
Os quantificadores, como o próprio nome já diz, são responsáveis por gerenciar a quantidade de ocorrências, isto é, quantas vezes o termo é encontado.
Por exemplo, para um número celular (sem DDD) temos 9 dígitos, então podemos pedir para sejam identificadas repetições de 9 números, certo? Quem garantirá esse número exato será o quantificador.
Porém, podemos também aceitar números telefônicos, que possuem 8 dígitos. Sendo assim, precisamos aceitar 8 ou 9, não é mesmo? Isso também será um trabalho para o quantificador!
Enfim, vamos para mais uma tabela rápida:
| Quantificador | Descrição | Exemplo |
|---|---|---|
| {n} | Repetirá exatamente n vezes | “[\d]{9}” |
| {n,m} | Repetirá entre n e m vezes (inclusive n e m) | “[\d]{8,9}” |
| {n,} | Repetirá n ou mais vezes (no mínimo n) | “[\w]{3,}” |
| ? | Ocorrerá Zero ou Uma vez | “[\d]?” |
| * | Ocorrerá Zero ou Mais vezes | “[5-8]*” |
| + | Ocorrerá Uma ou Mais vezes | “[F-J]+” |
Âncoras
As âncoras são importantes para definir e indicar posições, seja ela no string (texto) como um todo, na linha ou na palavra.
Diferente dos demais exemplos, estes nós já vimos anteriormente, então pense nessa parte como uma recapitulação e como forma de entender o uso real desses casos.
| Âncora | Descrição | Exemplo |
|---|---|---|
| \b | São os limites da palavra (início e fim) | “\bTeste\b” |
| \B | Não ser nos limites da palavra (inicio e fim) | “\Best\B” |
| ^ e $ | Respectivamente, início e fim da linha | “^[a-z]+$” |
| \A e \Z | Respectivamente, início e fim do texto | “\A[\w|\d]+\Z” |
Modificadores
Modificam a forma como são lidos e interpretados os padrões buscados, ou seja, modifica como o motor (engine) do RegEx vai agir.
Para usá-los, podemos definir tanto nas opções do RegEx, quando formos usá-los na programação, quanto por “(?_)” antes do termo a ser buscado, inserindo o modificador desejado no lugar do underline.
Em termos mais práticos, para ser case insensitive isto é, não importar com maiúscula ou minúscula, podemos usar “(?i)“.
Para termos um exemplo, o uso de “(?i)bylearn” irá retornar tanto “bylearn” quanto “ByLearn“, “BYLEARN“, “ByLeArN” ou qualquer outra forma da palavra, independendo das letras serem maiúsculas ou minúsculas.
| Modificador | Descrição | Exemplo |
|---|---|---|
| i | Case Insensitive | “(?i)bylearn” |
| x | Ignora espaços no termo buscado | “(?xi)te s te” |
| m | O Meta-caractere “ponto” aceita múltiplas linhas | “(?m)a.b” |
Grupos de Captura
Permitem dividir uma busca em subgrupos e retorná-los como resultado da captura.
Por exemplo, eu posso querer capturar “ByLearn” e ter como retorno dois sub-grupos (“sub-resultados”), sedo eles “By” e “Learn“.
Para definir tais grupos é muito simples: basta colocar o termo a ser buscado dentro de parênteses.
Sendo assim, para o exemplo acima teremos que usar: “(By)(Learn)“.
Eu posso também querer buscar um termo grande e retornar apenas um sub-termo, como por exemplo “Eu sou um ByLearner” retornar apenas ByLearn, sendo assim, eu posso usar: “Eu sou um (ByLearner)”.
Ah, e é claro, podemos usar tudo que já vimos até agora dentro dos grupos, como Meta-Caracteres, Meta-Sequência, Quantificadores e Classes de Caracteres.
| Grupo | Descrição | Exemplo |
|---|---|---|
| (a) | Captura o caractere a | “(a)(b)c” |
| (abc) | Captura o termo abc (tudo junto) | “(abc)” |
| (a|b|c) | Captura os caracteres a, b ou c | “(a|b|c)*” |
| (\w) | Captura a Meta-Sequência \w | “(\w)+” |
| (z+) | Captura grupos com um ou mais caractere z | “xy(z+)” |
Porém, algumas vezes queremos usar o parênteses sem capturar os dados, como por exemplo:
“Aqui vai ser x ou y e depois vai ser um número”
Dessa forma, o que eu vou fazer é agrupar as possibilidades (x ou y), mas não quero que sejam capturadas, então eu preciso usar um “Grupo de Não Captura”, que é dado pelo uso do (?:x|y), ou seja, eu coloco “?:” no início do grupo de não captura.
Vamos colocar isso em uma tabela também?
| Grupo | Descrição | Exemplo |
|---|---|---|
| (?:a|y) | Grupo que Não Captura o a|y | “(?:x|y)\d” |
Testando nossos padrões de RegEx
Agora já aprendemos a teoria das Expressões Regulares e já estamos prontos para pôr a mão na massa, não é mesmo?
Mas… onde iremos testar nossos RegEx? Será que já precisamos partir direto para a programação?
Por sorte, a resposta é não! Nós temos vários sites que servem como “ambiente de testes” para o RegEx e nos permitem ter um feedback visual instantâneo, sabendo se o que tentamos fazer irá ou não funcionar.
Como por exemplo, podemos testar o RegEx “[\d]{8,9}” em vários números de celular aleatórios e ver se vai pegar para todos os casos.
Dentre todos os sites disponíveis, o que eu acho mais completo e utilizo sempre que preciso é o RegEx101.
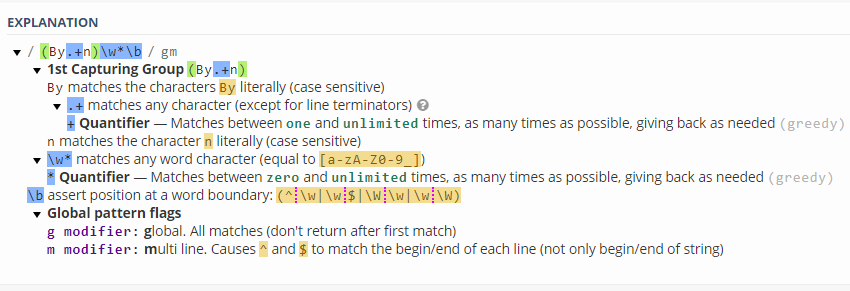
Nele, você consegue inserir padrões para buscas, textos para testar os padrões, uma explicação sobre o que o seu RegEx está fazendo, os resultados capturados e ainda gera códigos prontos para diversas linguagens.
Veja abaixo algumas imagens do site para entender melhor como usá-lo:
Colocando a mão na massa
Pronto, agora já não temos mais desculpas para não iniciarmos os testes!
Já sabemos a teoria, já sabemos onde testar e agora só falta mesmo brincar um pouco com o RegEx!
Para facilitar o aprendizado de vocês, além de passar os exemplos nós também enviaremos os links para acesso do teste no RegEx101, assim, vocês podem editar e interagir com cada exemplo.
Exemplo 1 – Extraindo anos
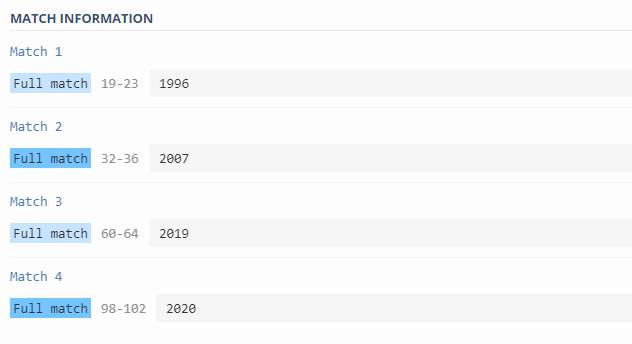
Vamos voltar para aquele exemplo lá do inicio da postagem, com aquele textinho cheio de números?
“O Felipe nasceu em 1996 e desde 2007 estuda programação. Em 2019 ele fundou a ByLearn. Em Maio de 2020 já existem milhares de ByLearners pelo mundo.”
Se repararmos bem, todos os anos possuem apenas 4 dígitos, não é mesmo?
Sendo assim, podemos apenas pedir ao RegEx que ele nos dê 4 dígitos, um depois do outro, como por exemplo:
[0-9][0-9][0-9][0-9]Veja esse exemplo aqui.
Porém, podemos deixar o padrão bem mais conciso e simples se usarmos Meta-Sequências e Quantificadores, como no caso abaixo:
\d{4}Veja esse exemplo aqui.
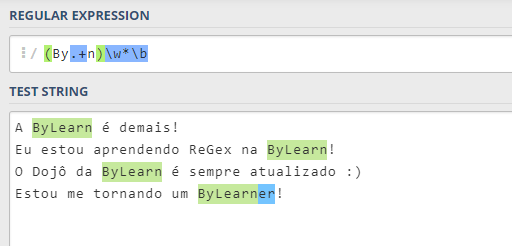
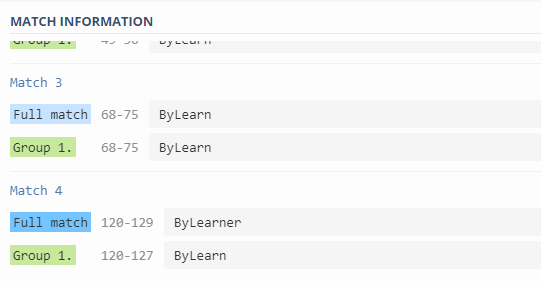
Exemplo 2 – Termos da ByLearn
Outro caso de uso das Expressões Regulares que falamos no início foi o de usar a mesma frase do exemplo anterior e extrair nossos termos, no caso, “ByLearn” e “ByLearner” (como chamamos nossos alunos e seguidores).
Sendo assim, podemos fazer com que o RegEx reconheça todas as palavras que iniciem por “ByLearn”.
Dessa forma, podemos utilizar o seguinte padrão:
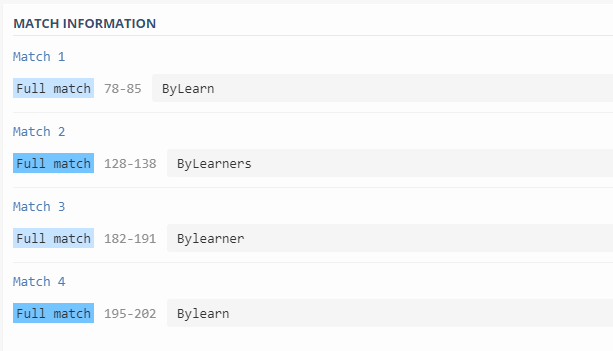
ByLearn\w*Veja esse exemplo aqui.
Atente-se que o “\w” não significa que são apenas letras, mas sim um conjunto alfanumérico, ou seja, composto de letras e números. Portanto, “ByLearn3r” também seria uma entrada válida.
Caso queiramos limitar para apenas letras, podemos usar o seguinte:
ByLearn[aA-zZ]*Veja esse exemplo aqui.
Ótimo! Estamos indo bem, porém, tem alguns alunos que nos enviam mensagem com “Bylearn“, usando o “L” na forma minúscula… Nós entendemos que o que vale e a intenção e não ligamos pra isso, afinal, a pronuncia continua a mesma 😄.
Sendo assim, vamos passar a aceitar o “L” minúsculo também? Para isso, vamos usar o “pipe“, o meta-caractere da barra reta, que significa “um ou outro”. Dessa forma, o RegEx será o seguinte:
By[L|l]earn[aA-zZ]*Veja esse exemplo aqui.
Exemplo 3 – Número de celular e telefone
Outro caso bem popular de uso das Expressões Regulares é para validar se estamos trabalhando com um número de celular ou telefone.
Precisamos, antes de tudo, saber as regras desses números:
- Celulares possuem 9 dígitos, sendo que o primeiro dígito é o 9;
- Telefones possuem 8 dígitos;
- Geralmente dividimos os 4 últimos dígitos através de um traço:
- ex: 91234-5678 ou 5478-8745
- Números iniciam com DDD, que são compostos pode 2 dígitos;
- Geralmente representamos o DDD entre parênteses e espaço:
- ex: (16) 91234-5678 ou (11) 5478-8745
Pronto! Agora é só começarmos a implementar, mas vamos com calma, vamos passo a passo, pode ser?
Lendo 8 ou 9 dígitos numéricos
Vamos começar vendo se temos 8 ou 9 números em sequência?
Para isso vamos usar um quantificador que espere por 8 ou 9 dígitos numéricos, no caso:
[\d]{8,9}Veja esse exemplo aqui.
Bom, vimos que ele já encontra sequências de 8 ou 9 dígitos. Porém, caso tenha 10 ou mais dígitos, ou a sequência esteja dentro de letras, ele também está dando certo, como nos casos abaixo:
1231231211
1asd13245687asdIsso aconteceu porque não estamos usando os “limites” da palavra, ou seja, não falamos para o RegEx algo como:
“Hey RegEx, certifique que a palavra inteira, do inicio ao fim dela, seja apenas isso. Ou seja, a palavra deve ser composta apenas de 8 a 9 dígitos e todos números.
Para isso é bem simples, podemos usar as âncoras, conforme aprendemos anteriormente, usando o “\b” para palavras ou “^” e “$” para linhas, nesse caso, como queremos um número por linha (e não vários), usaremos o código abaixo abaixo:
^[\d]{8,9}$Veja esse exemplo aqui.
Iniciando os celulares com dígito 9
Nosso próximo passo é agora definir que caso seja um número de celular, ele deve começar com o dígito 9. Ou seja, a lógica será:
“Se for celular, então tem um 9 e mais 8 dígitos numéricos, do contrário, apenas 8 dígitos numéricos.”
Para isso, no dígito 9, vamos usar o Meta-Caractere Quantificador “?” que aceita apenas Uma ou Nenhuma ocorrência. Em seguida, colocaremos mais 8 dígitos numéricos, ficando assim:
^9?[\d]{8}$Veja esse exemplo aqui.
Lendo no formato certo (Sem DDD)
Agora vamos começar a pegar o formato correto sem DDD, apenas separando os últimos 4 dígitos por um traço.
Para isso vamos quebrar nossa lógica em 3 partes:
- Antes do Traço;
- O traço;
- Depois do traço.
Na primeira parte teremos o 9, no caso de celulares, e mais 4 dígitos. Na segunda parte, temos o traço (caractere comum). Já na terceira parte, temos mais 4 dígitos.
Sendo assim, nosso código se tornará:
^9?[\d]{4}-[\d]{4}$Veja esse exemplo aqui.
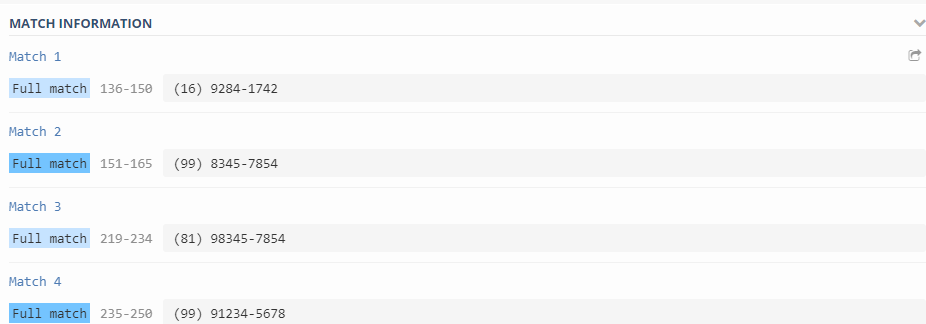
Inserindo o DDD
Agora vamos inserir o DDD no número do nosso telefone/celular.
Num primeiro momento, devemos lembrar que, para os parênteses, nós precisamos usar a tecla de escape, no caso, a barra (“\”). Para isso, podemos fazer “\(” e “\)“.
Também devemos lembrar que, depois de fechar o parênteses, temos um espaço, que pode ser usado com a Meta-Sequência “\s“.
Sendo assim, o nosso código final será o seguinte:
^\([0-9]{2}\)\s9?[\d]{4}-[\d]{4}$Veja esse exemplo aqui.
Exemplo 4 – Extraindo informações
Neste exemplo, vamos treinar um pouco o uso de Grupos de Captura. Para isso vamos extrair o valor do nome e idade de alguém em um texto.
Este texto será no formato chave e valor, algo bem comum na programação. No lado esquerdo temos uma Chave, que funciona como um identificador do que estamos trabalhando (como “Nome”) e Valor, o valor daquilo que estamos trabalhando (como “Qual é o nome”).
No caso, teremos Nome e Idade, ficando no seguinte formato:
- Nome: Felipe
- Idade: 23
Porém, teremos algumas “pegadinhas” (valores falsos que devemos filtrar), como por exemplo:
- Nome: 23
- Idade: Felipe
Também teremos informações extras que queremos ignorar, como:
- Profissão: Professor/Programador
Agora que já estamos com o exemplo preparado, vamos começar a implementar.
Como queremos retornar apenas o valor de Nome e a Idade, a primeira coisa que vamos fazer é forçar nosso Regex a ler apenas essas linhas.
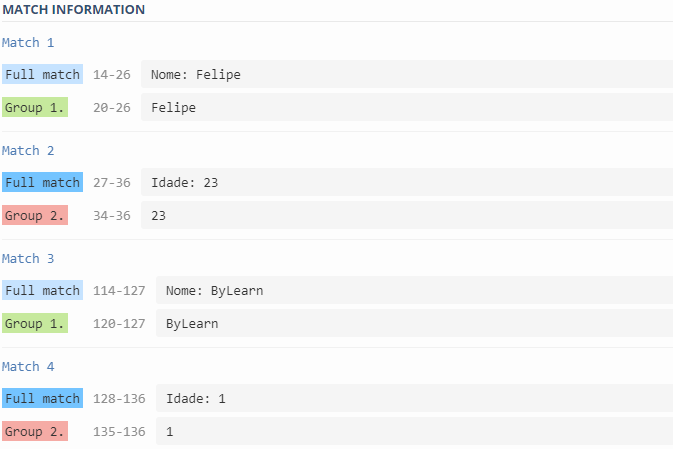
Como nós queremos retornar apenas os valores, então vamos inserir “Nome: ” e “Idade: “ (as chaves) em um grupo de “não captura”, da seguinte forma:
(?:Nome: |Idade: )Veja esse exemplo aqui.
Como vocês podem ver no exemplo acima, nós já identificamos apenas as chaves desejadas e as ignoramos no retorno. Agora basta começarmos a retornar os valores.
Para isso, vamos usar Grupos de Captura, lembra deles? São bem simples, basta colocar o que queremos capturar dentro de parênteses.
Como sabemos da pegadinha de poder ter números nos nomes e letras na idade, vamos colocar “([aA-zZ]+)” para nomes e “([0-9]+)” para idades, ficando assim:
(?:Nome: ([aA-zZ]+)|Idade: (\d+))Veja esse exemplo aqui.
Pronto, viu só? Agora nós conseguimos identificar termos chaves em um texto e retornar apenas o que desejamos.
Programando com RegEx
Não é surpresa alguma para você que leu até aqui que o RegEx está disponível na programação, não é mesmo?
Toda linguagem que se preze possui compatibilidade com ele e geralmente de uma forma bem fácil de usar.
O fluxo é sempre basicamente o mesmo, você escolherá um padrão (pattern) igual aos usados neste artigo e escolherá o texto base onde você buscará por esse padrão. O motor (engine) do RegEx da linguagem então irá procurar por uma correspondência (match) do seu padrão naquele texto.
Com isso, você pode tanto executar funções de substituição de texto (replace) quanto validação para saber se o texto realmente segue o padrão proposto (como no caso de validar e-mail ou checar se a senha é segura).
Embora toda linguagem possua suas Expressões Regulares implementadoras, você deve saber que a ByLearn foca muito no Python (que por sinal, temos até um treinamento completo disponível para você) e, portanto, vamos seguir apenas nesta linguagem aqui no Dojô, mas o conceito e uso será o mesmo em outras linguagens.
Usando Regex no Python
Eu sei que você já deve ter passado um bom tempo lendo esse artigo e quer um descanso, não é mesmo?
Pois bem, nesse texto nós vamos somente dar uma introdução ao uso de Expressões Regulares com o Python, porém, temos também uma postagem completa sobre o assunto aqui no Dojô que você pode ver clicando aqui.
Enfim, vamos lá? Já passou da hora de colocarmos em prática o RegEx no Python!
Criando o padrão
Antes de mais nada, é bom lembrar que o padrão de RegEx é universal, então se ele pegou no testador do site RegEx101 ele pegará também no Python (e no C#, Java, JS…).
Porém, cuidado: a maior parte das linguagens de programação utiliza o “\” como tecla de escape, sendo assim, ela pode dar conflito com nosso RegEx.
Podemos resolver isso de duas formas, mudando o “\” por “\\”, onde usamos o escape na própria barra, ou falando para a linguagem ignorar o escape e trate tudo como caractere literal (sem “poder especial”, sendo considerada como um caractere comum).
No Python a dica que eu dou é usar o “r” no início da string, assim, usamos a string como Raw String e passamos a tratá-la como uma String Literal.
Veja um exemplo abaixo:
Importando o módulo do RegEx
O Python utiliza o módulo re para executar o RegEx, sendo assim, precisamos importá-lo da seguinte maneira:
Efetuando nossa busca
Para buscarmos um padrão nós vamos executar o comando search (buscar, em inglês), da seguinte forma:
Como resultado temos None caso não encontre nada ou um objeto Match (correspondência) caso encontre.
Como saída (output) temos o seguinte:
<re.Match object; span=(19, 28), match='ByLearner'>Como podemos perceber, o objeto Match tem duas propriedades, o span e o match, sendo eles:
- span: Posição da ocorrência no formato (inicio, fim);
- match: O texto encontrado na ocorrência.
Sendo assim, podemos executar o seguinte código:
Dessa forma, temos como output o seguinte:
Encontramos o padrão no texto, entre os índices: 19 e 28Dominando o RegEx com o Python
É claro que apenas o search não é quase nada do que o bom uso das Expressões Regulares pode fazer no Python, porém, não vamos abordar tão profundamente neste artigo para não nos alongarmos tanto.
Extra: Gerando códigos com o RegEx101
Resolvi deixar um brinde aqui para vocês antes de finalizar o artigo, hehehe.
Depois de testarmos um padrão no RegEx101 podemos criar um código para diversas linguagens, tais como, Python, Java, C#, JavaScript, PHP e Ruby.
Para gerar esse código, devemos primeiro definir o padrão e inserir os textos de exemplo. Depois disso basta apertar em “Code Generator” no menu lateral esquerdo do site e será gerado um código na linguagem escolhida para trabalhar com as Expressões Regulares que definimos.
Veja um exemplo de código gerado:
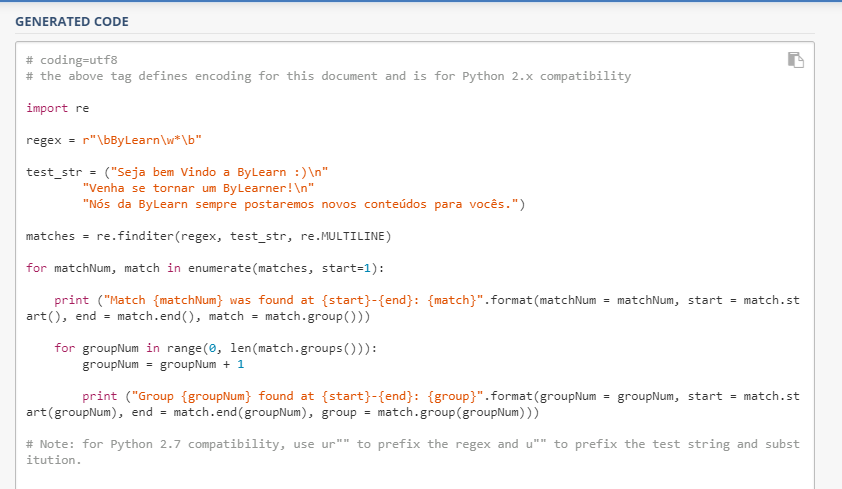
Como ninguém merece copiar um código de uma imagem, você pode acessar o código acima clicando aqui.
Conclusão
Como você pode ter percebido durante o texto, o uso de Expressões Regulares (RegEx) é uma mão na roda para os programadores e se torna uma tecnologia bem requisitada e necessária para o dia-a-dia.
Nós podemos tanto utilizar o RegEx para efetuar buscas poderosas quanto para validar padrões em textos (segurança de senhas, URLS e e-mails).
O uso das Expressões Regulares também independe da linguagem. Porém, nós da ByLearn preferimos o Python pela facilidade da sua sintaxe e versatilidade da linguagem.
Caso queira aprender mais sobre o RegEx no Python, você pode dar uma lista neste nosso outro artigo. Já caso queira aprender a dominar o Python de uma vez por todas, fica aqui o convite para conhecer nosso super treinamento.
Aproveitando, antes de finalizar o artigo, venho te fazer o convite de nos seguir nas redes sociais para receber diversos outros conteúdos e assinar nossa NewsLetter para não perder nenhum assunto.
Gostou desse artigo? Tem dicas para os próximos assuntos? Então deixe um comentário pra gente 😀
Newsletter
Se inscreva na nossa Newsletter para receber as principais novidades da ByLearn



